
Parallel and Distributed Computing
Parallel and Distributed Computing
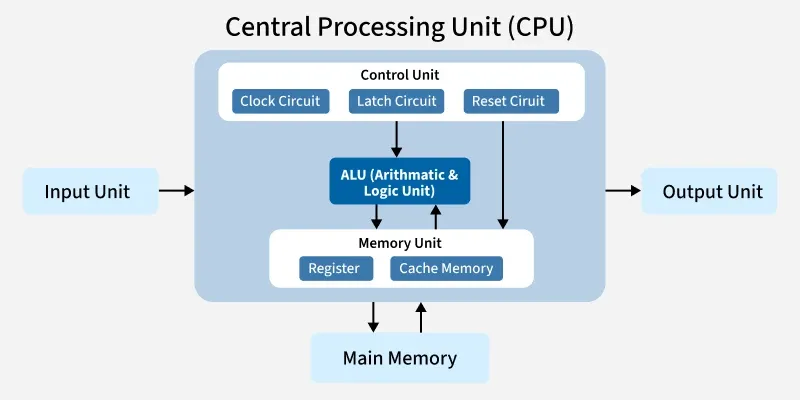
- What is CPU ?
{kind=link}
What is GPU ?
Difference between difference processing techniques ?
CPU, GPU, NPU and TPU - The Real Differences for AI/ML
CPU (Central Processing Unit) The classic processor in every computer. CPUs can run any software, including AI models, but are slower for deep learning due to fewer parallel cores. Best for:
- Traditional machine learning (scikit-learn, XGBoost)
- Running small models or prototypes
- General-purpose tasks and light inference
GPU (Graphics Processing Unit) GPUs are built for parallel processing. They are the backbone of modern deep learning, perfect for training and inference of models like CNNs, RNNs, and transformers (GPT, BERT, ResNet). Best for:
- Training and running large deep learning models
- Supported by all major AI libraries
- Flexible for many AI workloads
NPU (Neural Processing Unit) NPUs are specialised chips designed only for neural network operations, often embedded in smartphones and IoT devices. They run efficient models for vision, speech, and edge AI. Best for:
- On-device, real-time AI (face unlock, language translation)
- Battery-friendly AI in mobile and IoT
- Lightweight, efficient models
TPU (Tensor Processing Unit) TPUs are Google’s custom AI accelerators, tuned for TensorFlow and massive neural networks. Ideal for training and deploying large models at cloud scale. Best for:
- Scalable deep learning in Google Cloud
- Training and inference for big models (BERT, GPT-2, EfficientNet)
- High-speed tensor calculations
- Which AI models run on each? CPU: Any model, but best for classical ML, prototyping, and small-scale inference GPU: All deep learning models (CNNs, RNNs, transformers) NPU: Optimised mobile and edge models (MobileNet, tiny BERT) TPU: Large-scale neural networks in TensorFlow
Note DPUs (Data Processing Units): DPUs don’t run AI models directly, but they play a key role in modern AI infrastructure. They accelerate data movement, networking, and storage, freeing up CPUs and GPUs for computation making large-scale AI systems faster and more efficient.
- What is Parallel Processing ? What is parallel programming on GPU ?
Parallel transfer of data from CPU to GPU for computation using Cuda(C/C++) programming language
Story of School Team Work to Parallel Computing : Everyone have attended the school from their childhood to the Pre-College, Therefore Let’s Imagine a school with several classrooms. Each classroom is different—some bigger, some smaller, depending on what the school can afford, but every classroom is filled with students waiting for assignments.
Now, there’s a large pile of tasks that needs to be handled. Rule number one: no single classroom is allowed more than 1,024 tasks at any time. The work in each classroom happens differently, too—not every student tackles their own task immediately on their own.
Inside each classroom, tasks are handed out in special groups known as warps. Each warp is like a tight-knit team of students—32 of them move in perfect coordination, all working on their assigned tasks together, step by step without falling out of lockstep (everyone on the team does the same thing at the same time, or they wait for those who aren’t done yet).
At any moment, within a classroom, the number of tasks being actively worked on equals 32 times the number of warps that classroom can support. If, for instance, every classroom has 4 warps, then 128 (32 x 4) tasks are being processed at once in that classroom. Multiply that by the number of classrooms you have in the school: for N classrooms, a total of 32 x number of warps x N tasks are being worked on at the same moment.
The team size in each classroom (the number of warps) depends on how fancy or advanced your school is—that is, what kind of computer you have. So as more classrooms join, and each classroom handles more warps, the whole school can get through that mountain of tasks much, much faster.
What we have learn from this story about the parallel processing on GPU devices ?
- The “school” represents a GPU device.
- Each “classroom” is a CUDA thread block.
- The number of classrooms is variable, like the number of thread blocks being launched depending on work.
- Each classroom (thread block) can handle a maximum of 1024 tasks (threads in a block).
- Students in classrooms correspond to individual CUDA threads.
- Within each classroom, tasks are executed in groups called “warps.”
- A warp consists of 32 threads that execute instructions together simultaneously in lockstep.
- The number of warps per classroom depends on GPU architecture.
- At a given time, the number of tasks running = 32 (warp size) x number of warps x number of classrooms.
- This structure allows parallel processing of many tasks simultaneously, speeding up completion.
- The analogy highlights how CUDA organizes parallel execution with hierarchical thread grouping: grids of blocks, blocks of threads, threads in warps.
- Workload is divided efficiently among threads, with synchronization inside blocks (classrooms) but not between them.
- This provides scalability as more blocks can be launched on multiple GPU multiprocessors.
Physical : These are observable and have fixed quantity such as students.
Streaming Processors(SPs/Cores) : They are main processing unit on GPU and capable of executing computation concurrently on multiple data elements. Thus, SPs(Cores) as Individual Students and more Cores means the greater the number of tasks that can be processed concurrently.
Streaming Multi-Processor(SM/multi-processor) : a collection/group of SPs(Cores) like a classroom that accommodates multiple student(SPs/Core). Therefore, SM acts as a higher-level unit that manages and coordinates the execution of tasks across the SPs within it.
Note :
SM = classroom (manages execution, resources, scheduling)
Core (SP) = student (executes individual tasks/threads)
The number of Streaming Multiprocessors (SMs) and Streaming Processors (SPs or cores) varies by GPU model and architecture, with SMs being higher-level units that manage groups of cores, and the total counts are fixed for a given GPU design. For example, a GPU might have 16 SMs, each containing 32 or more cores, but the exact numbers depend on the specific NVIDIA GPU model.
Logical : These are’t directly observable but can be imagined or conceptualized with an unspecified quantity such as tasks.
What are the CUDA threads, blocks and grids ?
A thread in CUDA represents a single unit of work or task, just like one job that needs to be done. It is the smallest execution unit, and each thread runs independently.
A block is a group or collection of threads. These threads in a block work together and can share data via fast shared memory. The block size (number of threads in a block) is limited by hardware — typically up to 1024 threads per block. This is because all threads in a block execute on the same Streaming Multiprocessor (SM) and share its limited resources.
The grid is a larger structure made up of multiple blocks. Blocks within a grid perform the same kernel function but work on different parts of the data or tasks. The grid size can vary depending on the total workload.
Using your example: If there are 6 blocks and each block contains 12 threads, then the whole grid has 6 × 12 = 72 6×12=72 threads executing in parallel.
Threads and blocks are indexed to identify their position, similar to a matrix coordinate system:
blockIdx identifies which block in the grid the thread belongs to.
threadIdx identifies the thread within its block. These indices help a thread know exactly what data to work on.
We divide threads into blocks because of two main rules:
Maximum Threads per Block Limit: Each block can have a maximum of (usually) 1024 threads to avoid resource contention on an SM.
Warp Execution Limits: Threads execute in groups of 32 called warps. If you put all 1024 threads in a single block, only 32 threads (one warp) execute simultaneously, and others wait, resulting in sequential execution in chunks. Splitting threads into multiple blocks allows many warps to run concurrently on different SMs, maximizing parallelism.
The cake-eating analogy:
Eating 32 cakes sequentially (one warp) inside a single block takes longer.
Dividing 1024 cakes across 32 blocks of 32 threads lets you eat all 1024 cakes at once in parallel, speeding up the task dramatically.
Thus, Thead is one single task/job, block is a group of threads working togathe, limited to usually 1024 threads and grid is a collection of blocks doing the same kernel function over the full workload.
Threads and blocks have indices to identify their work division.
Dividing threads into smaller blocks avoids hardware limits and enables more efficient parallel execution through multiple warps running concurrently.
This hierarchical structure (thread → block → grid) underlies CUDA’s ability to perform massive parallel computation effectively.
In short, warps are the execution units sending groups of 32 threads through instructions together on the GPU hardware, while blocks are logical groups of threads that share resources like shared memory and coordinate with synchronization to collaboratively solve parts of the problem.